打造AI智能深度研究引擎:Dify工作流实战指南(附图详解)
引言:让AI成为你的超级研究员 🚀
你是否遇到过这样的问题?面对复杂的科研选题、市场调研,或者代码排错,传统搜索总是让你“一查十不全”,需要多次切换关键词、反复筛查结果,效率低下且易遗漏关键信息。如今,Google Gemini、ChatGPT等顶级AI平台已开始集成“Deep Research”能力,帮助用户系统性挖掘知识,自动识别信息缺口并输出结构化报告。
本文将为AI开发者、自动化产品经理、数据工程师及科研团队详细解析,如何基于 Dify 平台用低代码/无代码方式快速搭建一套智能深度研究工作流,让AI不只是“查资料”,而是学会像专家一样发现、追问、总结与引用,为你的研发和决策增添一对“超级大脑”👩🔬🤖。
一、Dify深度研究工作流:整体设计思路
本指南所述 Deep Research Workflow 由三大核心环节组成:
- 研究意图识别:收集主题与上下文,明确目标。
- 动态循环探索:多轮自动查找知识点、识别缺口、聚合发现。
- 结构化总结输出:整合所有信息,生成规范引用的分析报告。
这种模式正好复刻了人类资深研究员的思考路径:“我已经知道什么?还缺哪些?下一步该去哪找?”——但一切都可以自动化完成!
二、Phase 1:研究基础搭建
1. 配置 Start 节点:输入核心参数
- research topic:明确研究主题
- max loop:设定本次探索最大循环次数(避免死循环/资源浪费)

2. 背景知识预获取
建议接入 Exa Answer 工具,先爬取部分基础资料(如术语解释、现有共识),为后续AI理解和推理打下底层认知基础。
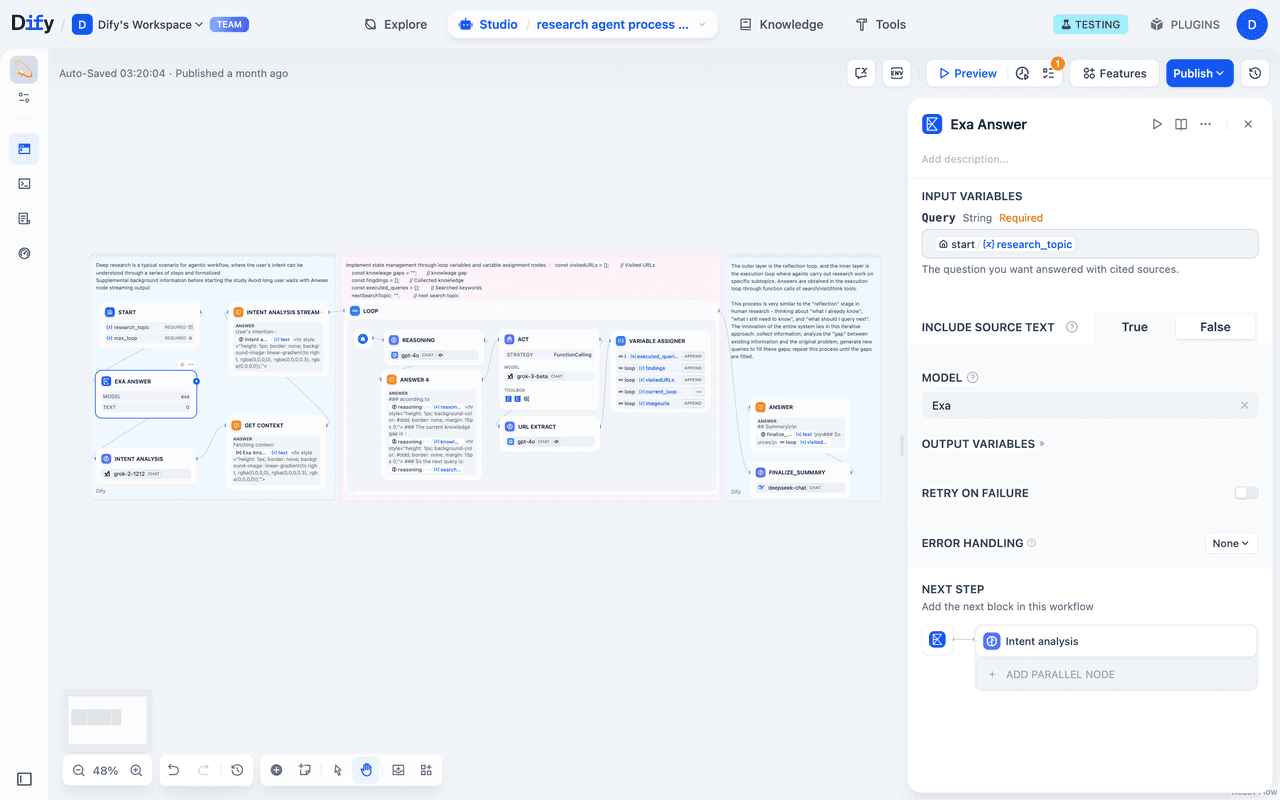
3. 意图分析:LLM节点深挖真实需求
通过大模型节点提炼用户需求,将表面问题转化为可细分、可追溯的深度研究子问题。

三、Phase 2:动态循环——知识发现与迭代
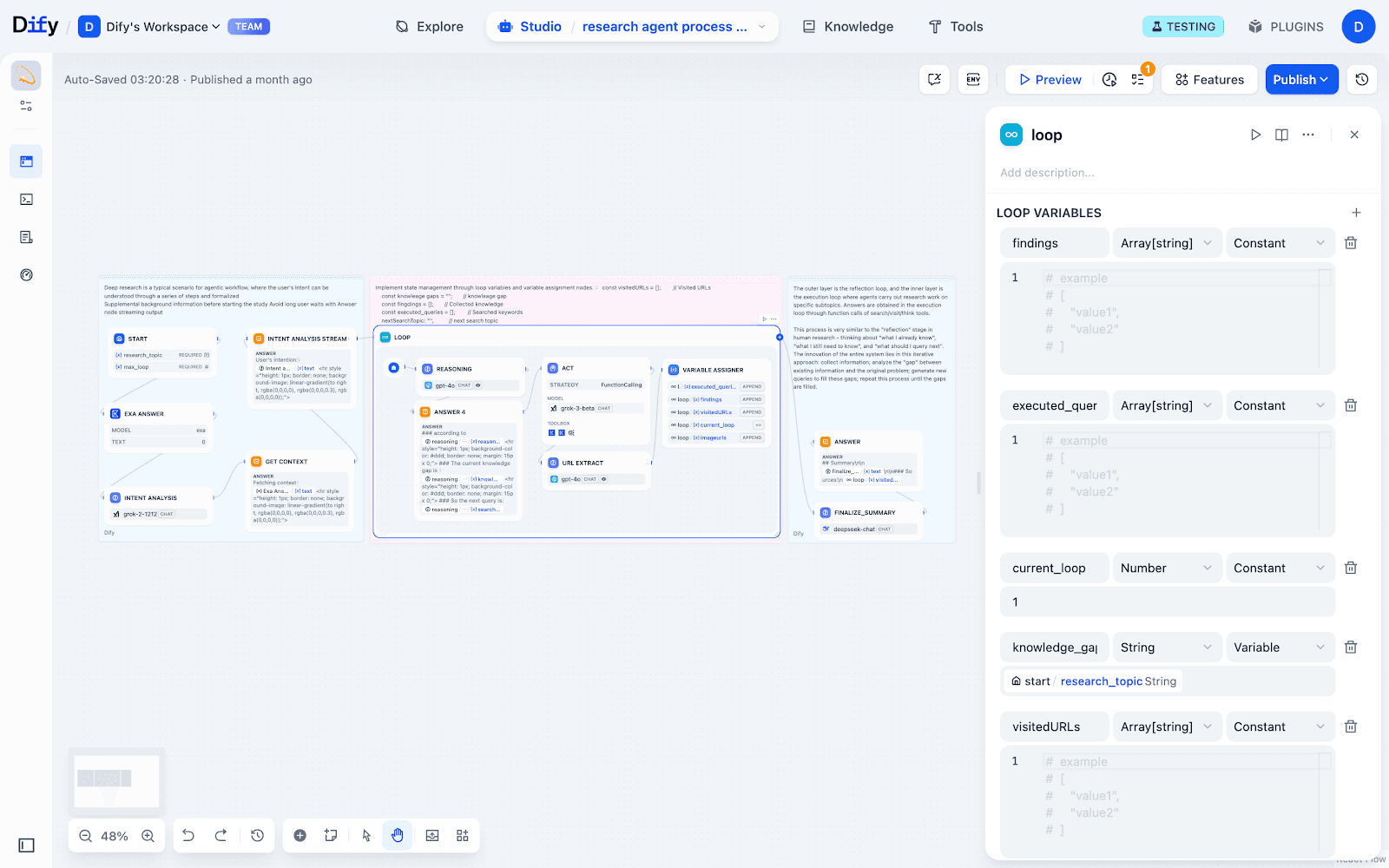
1. Loop节点:信息累积的核心引擎
Loop节点实现信息跨轮迭代传递,实现“边搜集边归纳”:
- findings:每轮新发现的知识点
- executed_querys:历史检索防止重复
- current_loop:循环计数
- visited_urls/image_urls:追踪所有来源便于引用
- knowledge_gaps:动态暴露的信息盲区
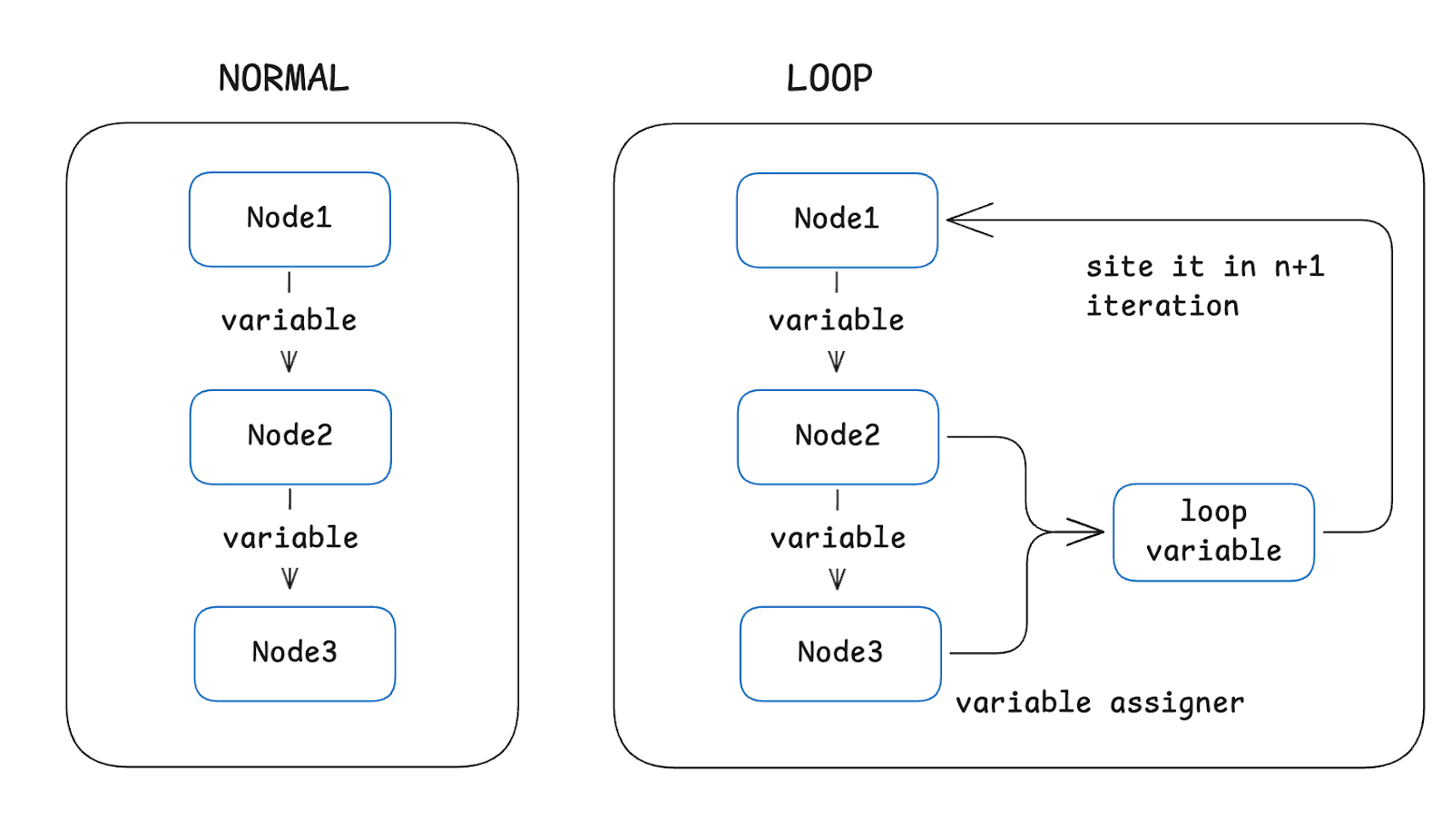
对比传统流程:
- 普通变量只单向传递(Node 1→2→3)
- Loop变量可回溯历史迭代,像知识网络一样累积优化,极大提升效率与准确性
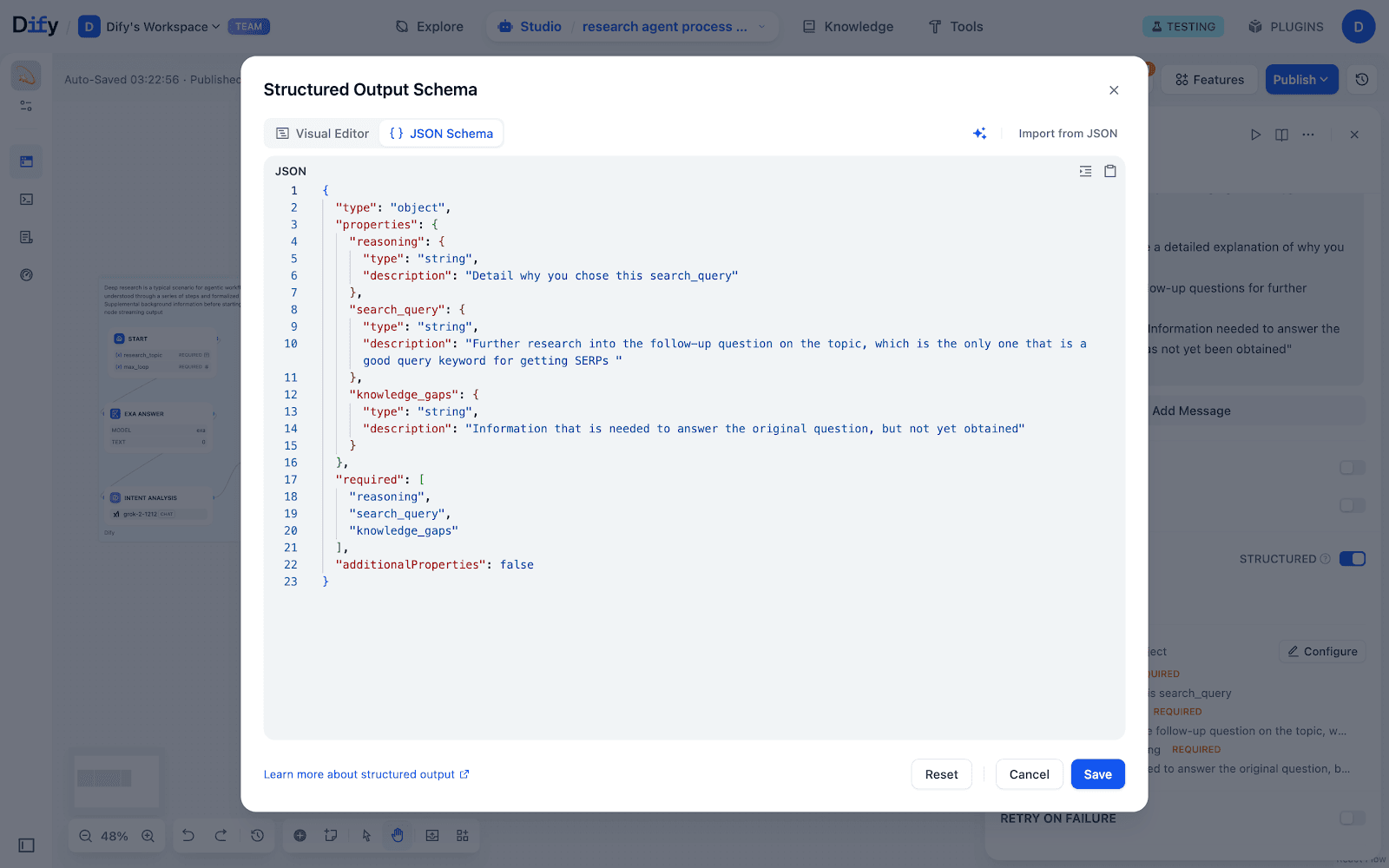
2. Reasoning节点:结构化输出,问得更精准
借助 Dify 的 Structured Output Editor,将LLM输出标准化为如下JSON格式:
{
"reasoning": "行动路径选择依据",
"search_query": "用于新一轮探索的精准查询",
"knowledge_gaps": "仍需补足的知识点"
}这样,下游节点即可自动解析推理链路、检索目标与知识缺口,实现高度自动化决策。

3. Agent节点:自动选择工具执行行动
Agent节点相当于AI“行动派”,根据 Reasoning 节点给出的search_query,自动调用:
- exa_search:全网检索
- exa_content:指定URL内容抓取
- think:类Claude思考工具,用于自我反思和规划下一步(类似科学家做笔记和归纳)
如此,每一次迭代不仅能找新资料,还能不断自我完善行动策略。
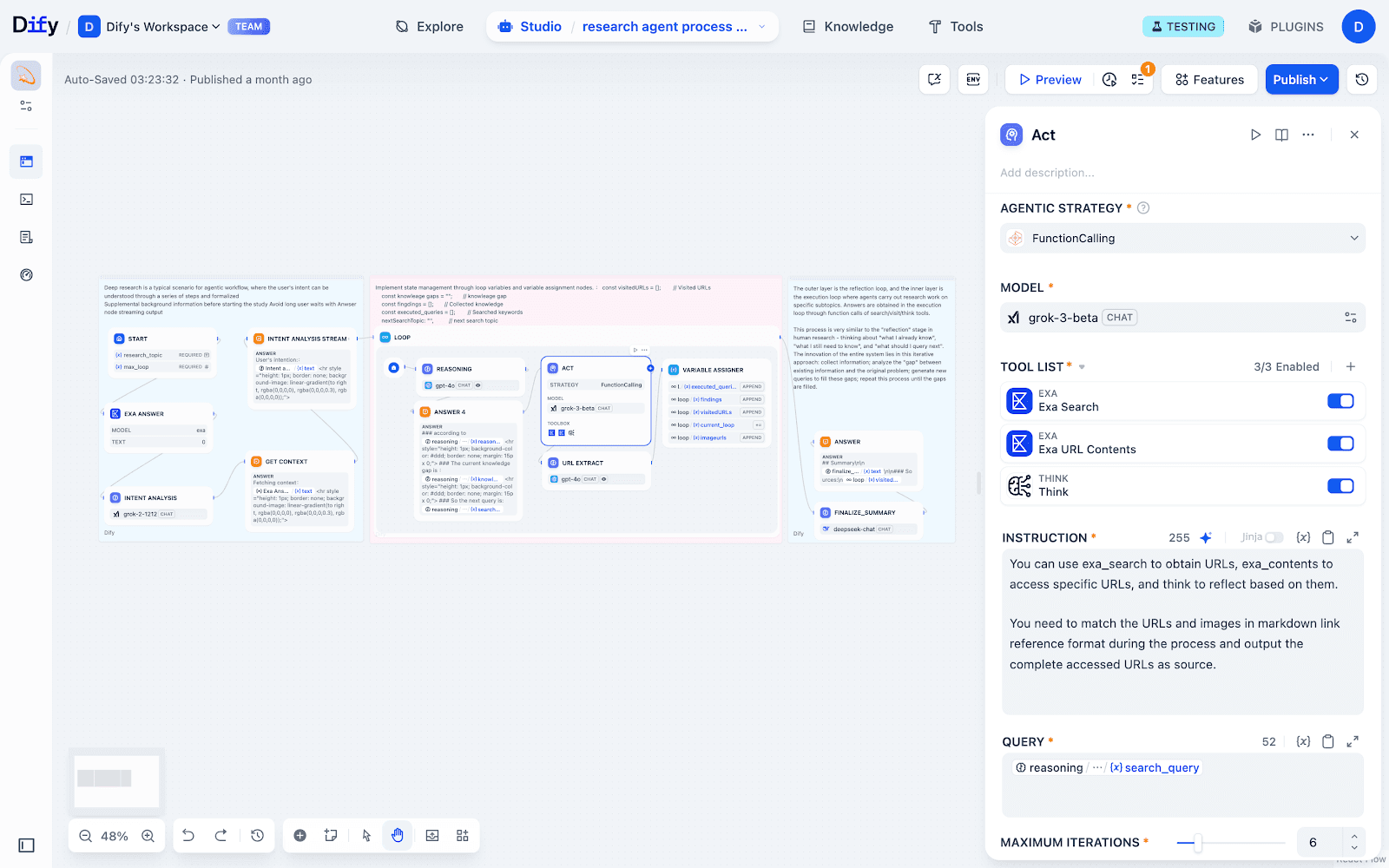
4. 结果追踪与状态管理
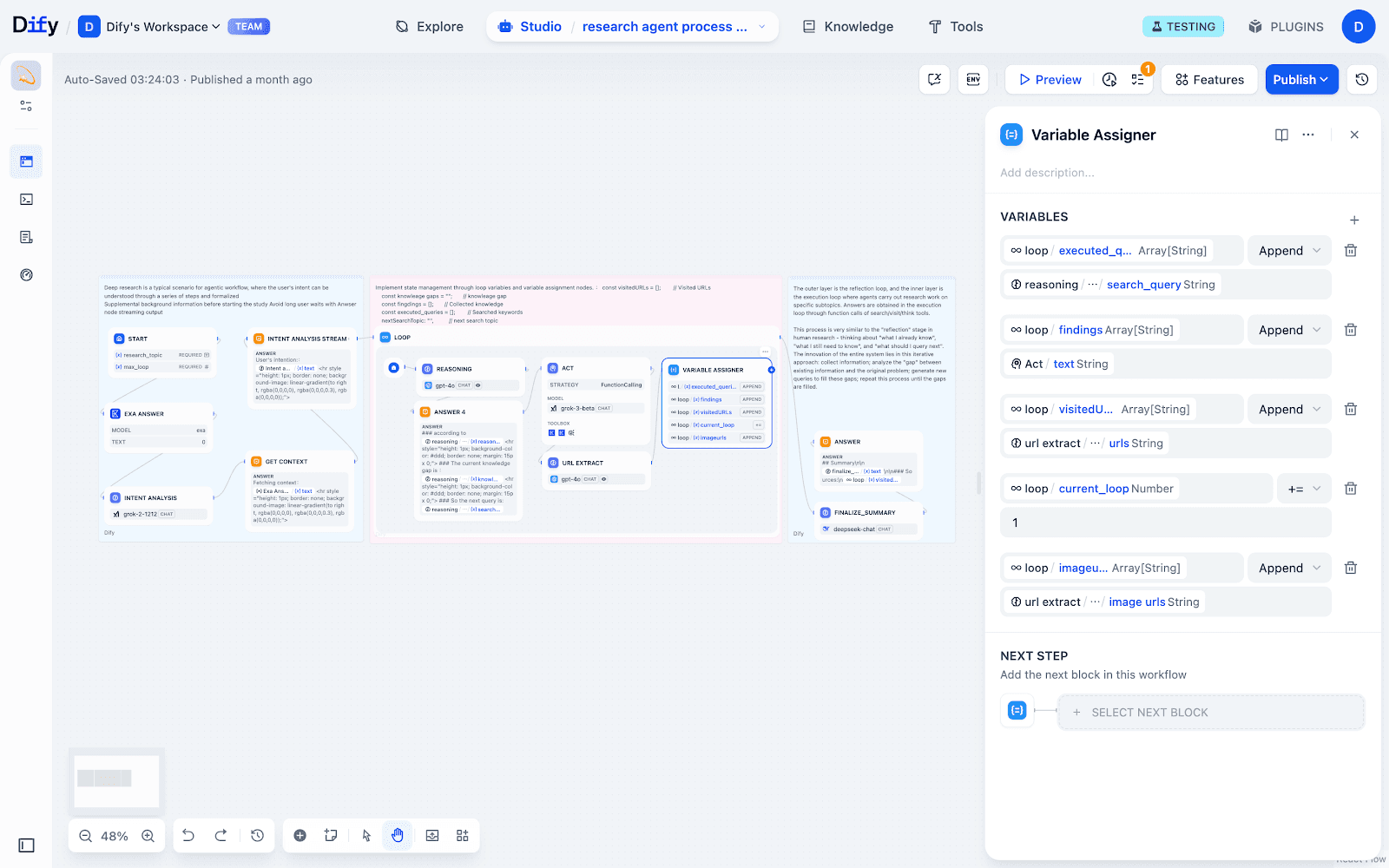
每轮循环结束后,通过 Variable Assigner 节点,把本轮新变量写回全局状态,为下次循环打基础。
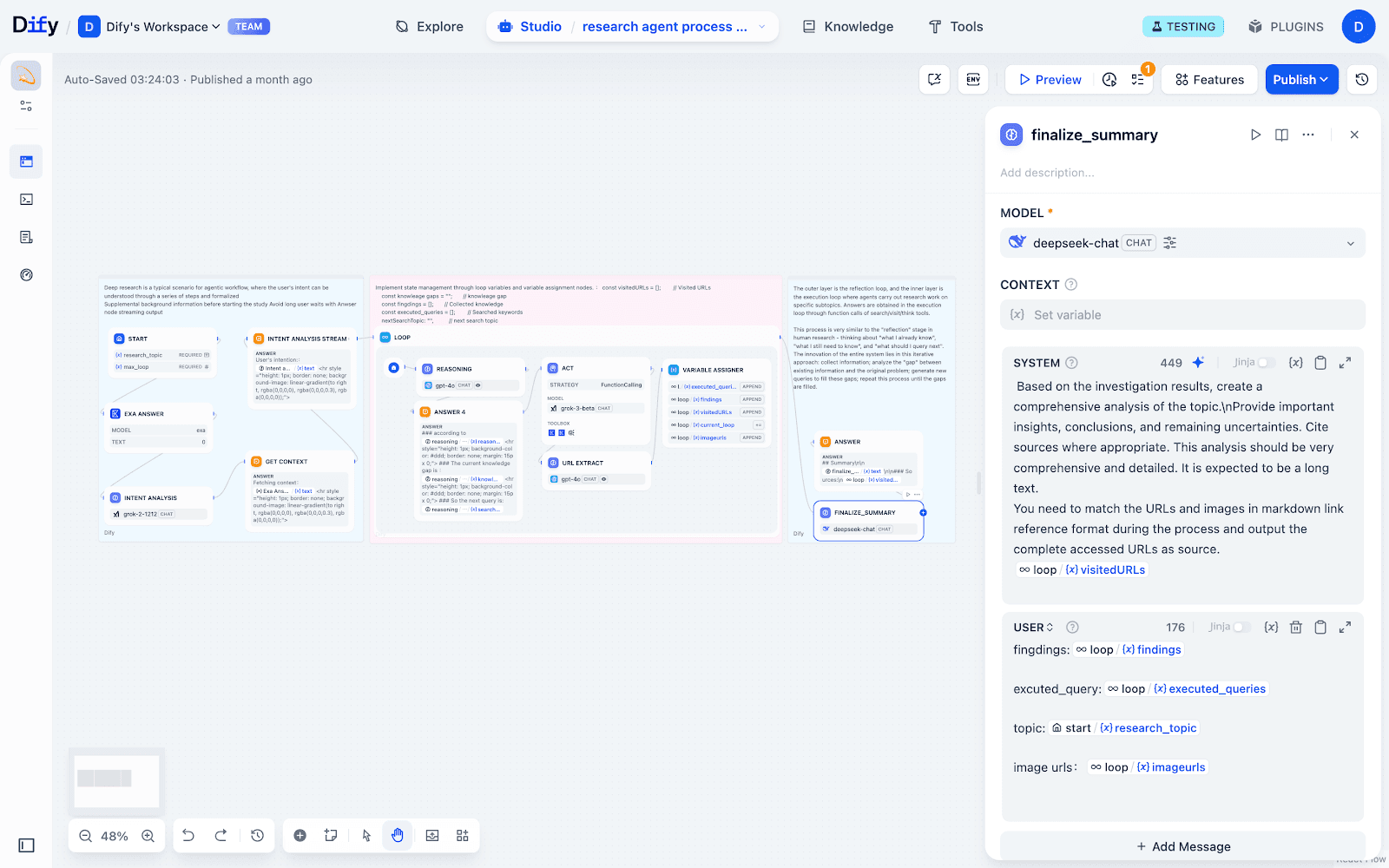
四、Phase 3:结构化总结与学术引用
全部探索完成后,通过 Final Summary 节点将所有 findings、来源URL和图片等汇总成带有Markdown引用格式的完整报告。并可在关键节点插入 Answer节点,实时推送进展,方便用户追踪每一步的结果和引用出处。
五、结论与展望
通过 Dify 的深度研究工作流,我们不仅复刻了专家级的推理和检索过程,更将其数字化、自动化,大幅提升了团队的知识发现与决策效率。未来,真正高效的研究不是“数据越多越好”,而是要“更智能地利用数据”——而你只需专注于提好问题,其余交给AI。
互动讨论 🎯
你是否尝试过用 AI 驱动的深度研究工具?你认为 Dify 的这类工作流还可以如何优化?
欢迎在评论区留言交流想法,或分享你在实际项目中的经验!别忘了点赞、转发给同样关注AI生产力工具的小伙伴哦~
本文参考自 Dify官方博客 Deep Research Workflow 指南。
更多技术细节见 Dify官方文档 或 GitHub 源码。