模块化单体架构中的数据隔离实践:四大模式深度解析
模块化单体(Modular Monolith)作为介于传统单体与微服务之间的架构形态,近年来受到众多企业级开发团队青睐。它既承袭了单体架构的开发效率,又引入了模块边界和演进灵活性。那么,在这种架构下,如何实现高质量的数据隔离,保证模块间的低耦合与独立性?本文将结合实际场景,系统梳理四种数据隔离模式,并通过配图深入剖析各自的实现要点、适用场景及演进思路。
引言:为何模块化单体需要数据隔离?🔒
在大型企业级应用开发中,如何既快速交付,又为未来的演进(比如微服务拆分)打下坚实基础,一直是架构师们关注的重点。模块化单体架构以其“先分而后合”的理念,将系统划分为若干边界清晰、责任独立的模块。
然而,如果数据层面仍旧混杂——模块间随意访问表、共享数据结构——那么业务逻辑即使分离,也难以避免耦合和维护困境。因此,“让每个模块只访问自己的数据”就成了模块化单体中的黄金法则。
核心收益包括:
- 模块独立性提升,业务边界更加清晰
- 降低变更带来的连锁风险
- 为未来向微服务迁移做好铺垫
💡 小贴士:模块间数据交互应通过公共 API,而非直接跨表查询!
数据隔离四大模式全景解析
1️⃣ 级别一:分表(Separate Table)
做法说明: 所有模块的数据表共存在于同一个数据库实例下,但每个表归属于特定模块。
优点&局限:
- 💡 实现简单,上手成本低
- ⚠️ 随着表数量增加,难以追踪表归属;约束规则依赖人工遵守
示意图:
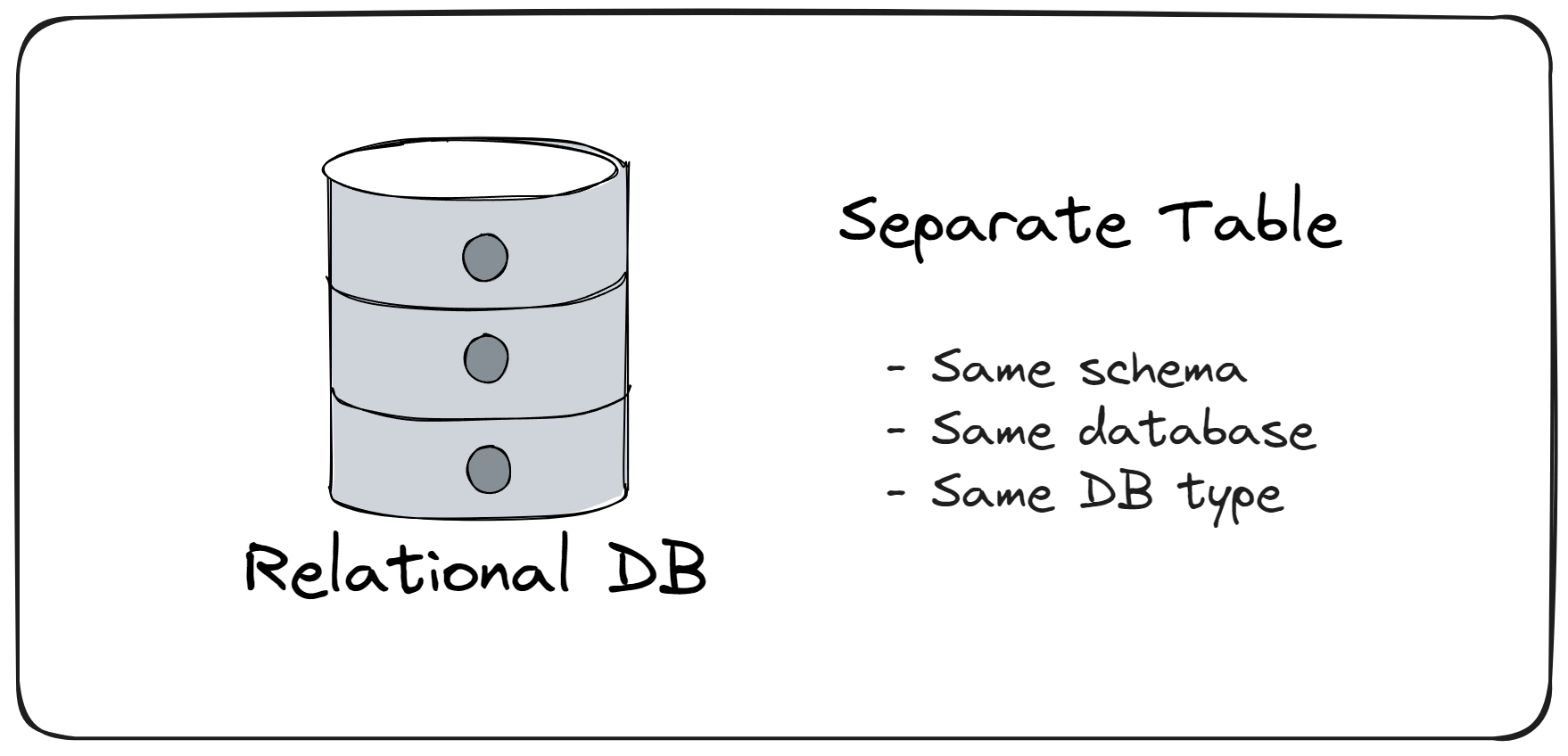
适用场景: 小型项目或早期原型开发,后续可平滑升级至更高隔离等级。
2️⃣ 级别二:分库模式下的分 Schema(Separate Schema)
做法说明: 在同一数据库实例下,不同模块拥有独立的 schema(或 namespace),实现更清晰的逻辑隔离。
优点&局限:
- 📦 明确区分不同模块的数据归属
- 🛡️ 可结合 ORM(如 EF Core 多 DbContext)和架构测试自动防止跨模块访问
- 🚀 易于管理和扩展,是最推荐的起步方案
示意图:
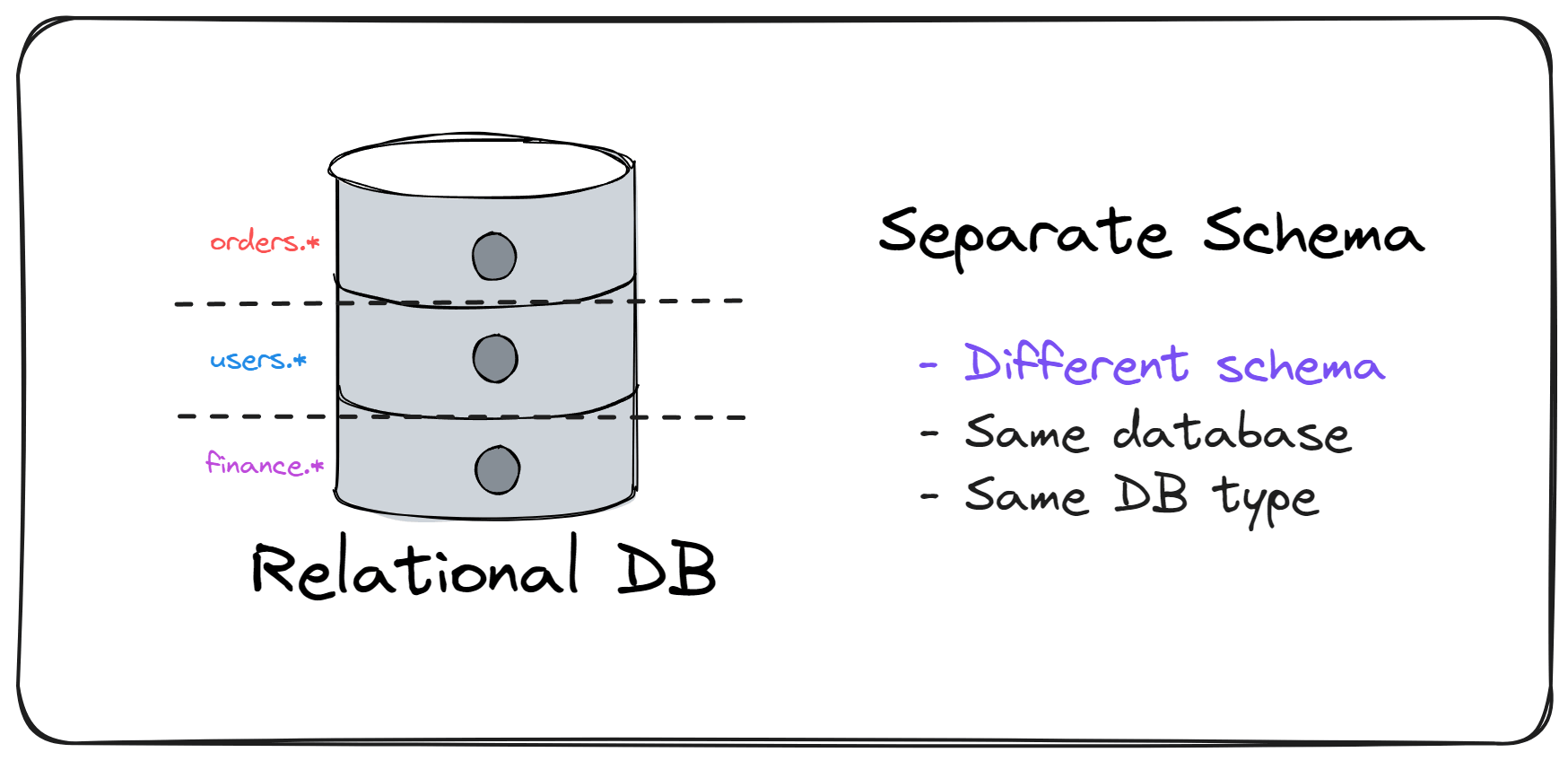
实践建议:通过自动化测试或代码规范,强制禁止跨 Schema 查询,进一步巩固隔离效果。
3️⃣ 级别三:物理分库(Separate Database)
做法说明: 每个模块的数据独立存放在不同的数据库中,实现物理层级的完全隔离。
优点&局限:
- 🏰 隔离彻底,安全性和可维护性最佳
- ⚙️ 增加运维复杂度,需要管理多个数据库实例
- 🔗 是向微服务迁移前的重要步骤
示意图:
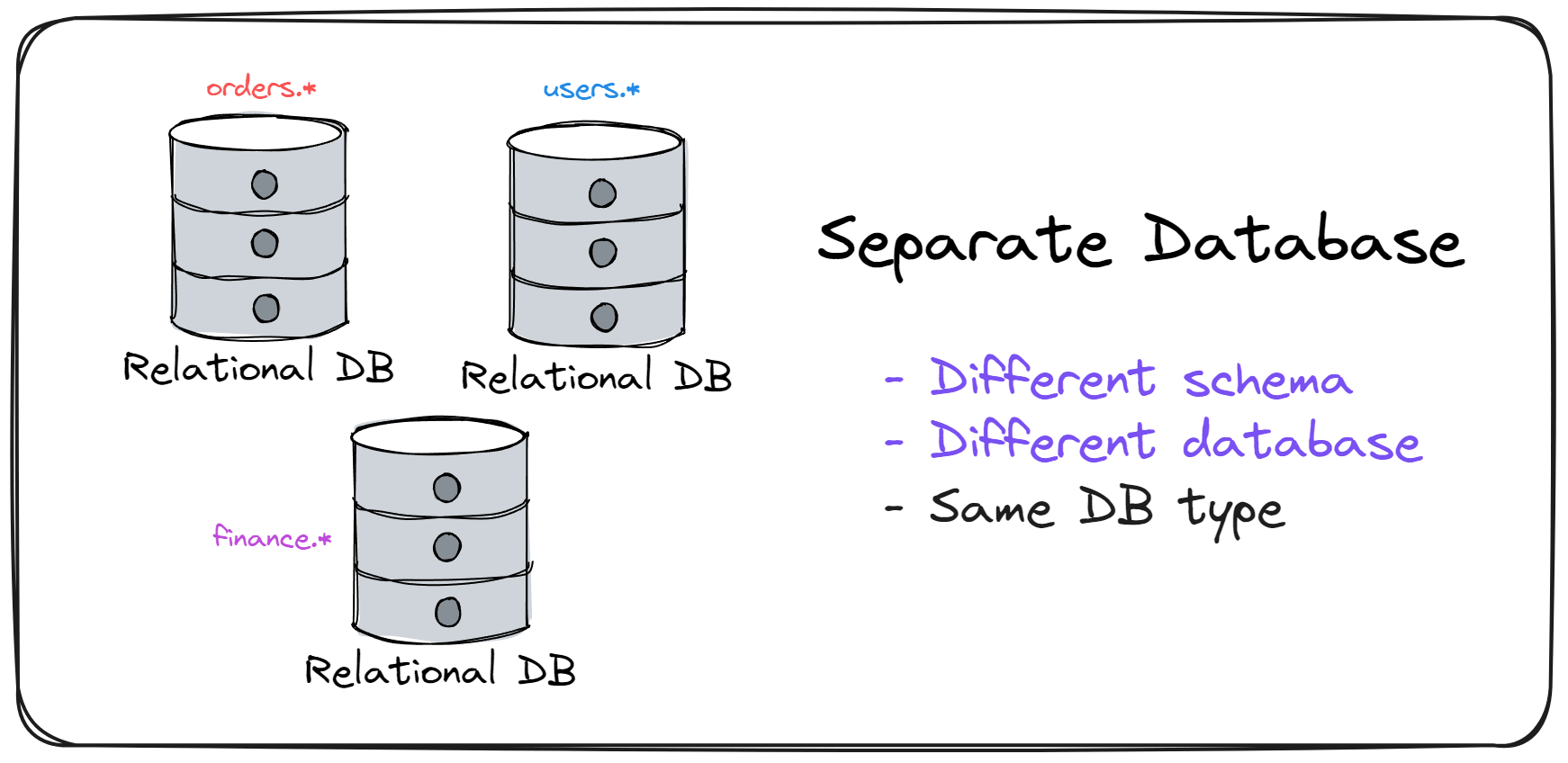
应用举例:当某一模块需单独扩展、重构或抽取为微服务时,提前迁移到独立数据库能极大减少后续工作量。
4️⃣ 级别四:多类型持久化(Different Persistence)
做法说明: 不同模块不仅使用不同数据库,还可以选择完全不同类型的持久化技术。例如,一个模块用关系型数据库(SQL),另一个用文档数据库(NoSQL)、图数据库等。
优点&局限:
- 🧠 灵活应对多样业务需求,技术选型自由度大
- ⚠️ 系统复杂度显著上升,需要团队具备多栈能力
示意图:

总结&演进建议
正如我们所见,模块化单体的数据隔离可以逐步演进,从最基础的“分表”到“多类型持久化”,每一级隔离都带来更强的独立性,也对团队提出了更高的设计和运维要求。
最佳实践建议:
- 初期项目推荐采用“分 Schema”实现逻辑隔离
- 随着业务增长、需求复杂化,可逐步向“分库”甚至“多类型持久化”升级
- 全程用自动化工具强化边界管控,避免人为越界
你的观点?欢迎留言讨论!
作为架构师/高级后端开发者,你所在团队目前采用的是哪种数据隔离策略?你如何看待“先模块化、再微服务”的演进路线?欢迎在评论区分享你的经验和见解,也可以点赞、转发本文给有需要的同事!🚀