NuGet Restore算法的华丽重生:性能提升16倍,团队效率爆炸性增长! 🚀
背景故事
在.NET平台上,NuGet Restore是保证项目依赖关系完整性的重要环节。然而,随着项目规模和复杂度的增加,旧版NuGet Restore算法渐显疲态。一个微软内部团队(我们称之为TeamX)的Restore时间暴增至30分钟,这成为了优化的催化剂。于是,来自NuGet、Visual Studio以及.NET团队的工程师们共同展开了一场历时6个月的技术攻坚战。最终,他们不仅将Restore时间缩短到2分钟,还为全球开发者带来了巨大的效率提升!
以下是关于这次重写历程的深入分析,从技术挑战到实际实现,带你一窥NuGet Restore算法的蜕变。
历史回顾 📜
初期NuGet的设计思路
在2011年,NuGet主要用于解决单框架项目的依赖问题。当时的packages.config文件记录了所有依赖包,NuGet只需简单读取并下载这些包即可。
如下是一个ASP.NET项目的packages.config示例:
<?xml version="1.0" encoding="utf-8"?>
<packages>
<package id="Antlr" version="3.5.0.2" />
<package id="bootstrap" version="5.2.3" />
<!-- 更多包 -->
</packages>虽然这种方式简洁,但随着项目规模扩大和依赖复杂化,手动维护依赖变得困难。尤其是多框架支持(例如.NET Framework和.NET Core)的出现,更让依赖关系变得如同“蜘蛛网”。
转向PackageReference模式
为了解决这些问题,NuGet引入了PackageReference模式,仅需定义直接依赖关系,而所有传递依赖均由Restore过程自动计算。这极大减少了开发者的工作量,同时提高了依赖解析的准确性。
如下是一个使用PackageReference定义的项目文件:
<Project Sdk="Microsoft.NET.Web.Sdk">
<ProperyGroup>
<TargetFramework>net472</TargetFramework>
</ProperyGroup>
<ItemGroup>
<PackageReference Include="bootstrap" Version="5.2.3" />
<!-- 更多直接依赖 -->
</ItemGroup>
</Project>技术挑战与瓶颈 ⚡️
为什么解析依赖图如此困难?
NuGet Restore需要处理复杂的有向图,其中节点(即包)还带有版本信息。例如:
- 若某个包声明了依赖版本范围,如
>=1.0.0,NuGet需要选择最优版本。 - 如果多个包对同一依赖有不同版本要求,NuGet必须进行版本统一。
如下图所示,当两个包的子依赖版本冲突时,NuGet需要优先选择更高版本:
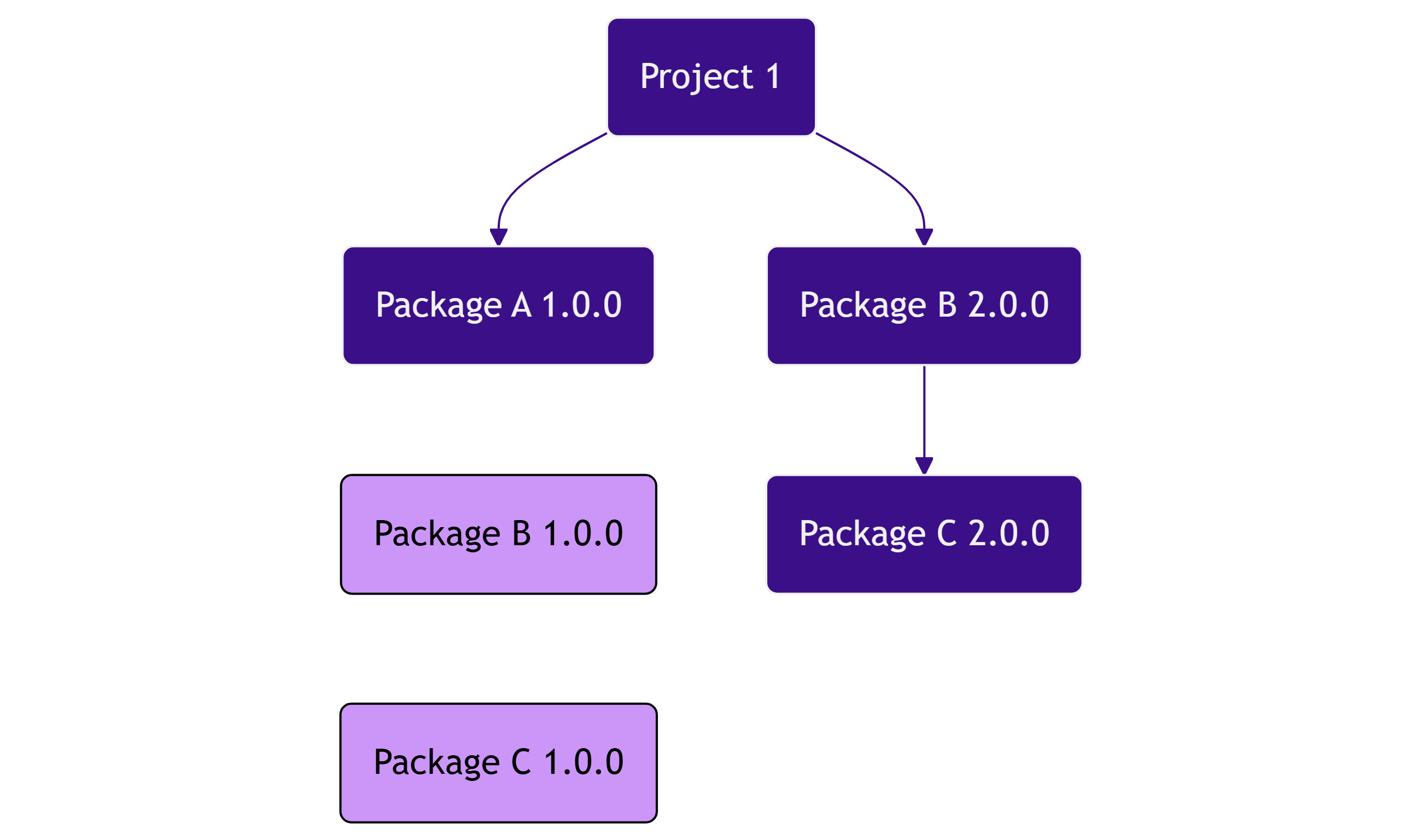
旧算法的局限性
旧版算法采用递归方式构建完整依赖图,并逐层解析。这种深度优先的方法虽然逻辑清晰,但在处理大型图时会因过多任务排队和内存分配导致性能瓶颈。例如,对于一个包含2500个项目的大型解决方案,其Restore操作可能需要迭代9次,总计处理超过160万个节点!
此外,递归还让调试和优化难上加难。如下是旧算法的一段伪代码:
public static Node<T> CreateNode<T>(T item)
where T : class
{
Node<T> node = new Node<T>(item);
foreach (T child in node.GetDependencies())
{
Node<T> childNode = CreateNode(child);
node.Children.Add(childNode);
}
return node;
}性能优化初探 🔧
工具与策略
工程师团队使用了多种工具进行性能分析,例如PerfView和Visual Studio的性能分析器。他们发现:大量内存分配是主要瓶颈,尤其是递归调用中生成的大量状态机对象。
优化案例之一是避免不必要的内存分配,例如以下代码中对集合进行多次枚举:
if (values != null && values.Any())
{
writer.WriteNameArray(name, values);
}通过改写逻辑,他们成功减少了重复计算并优化了枚举操作:
var enumerator = values.GetEnumerator();
if (!enumerator.MoveNext())
{
return;
}
_writer.WritePropertyName(name);
_writer.WriteStartArray();
_writer.WriteValue(enumerator.Current);
while (enumerator.MoveNext())
{
_writer.WriteValue(enumerator.Current);
}
_writer.WriteEndArray();初步成果 🎯
尽管优化后的旧算法将TeamX的Restore时间从32分钟缩减到16分钟,但随着项目规模增长,这种改进仍不足以应对未来挑战。因此,工程师们决定彻底重写算法。
新算法的诞生 🌟
原型验证
新算法摒弃了旧版“构建完整依赖图再解析”的模式,而是采用“逐步决策”的策略,即在遇到每个节点时立即做出最优选择。这不仅减少了内存使用,还避免了重复图遍历操作。
如下是新算法解决冲突时的策略流程图:
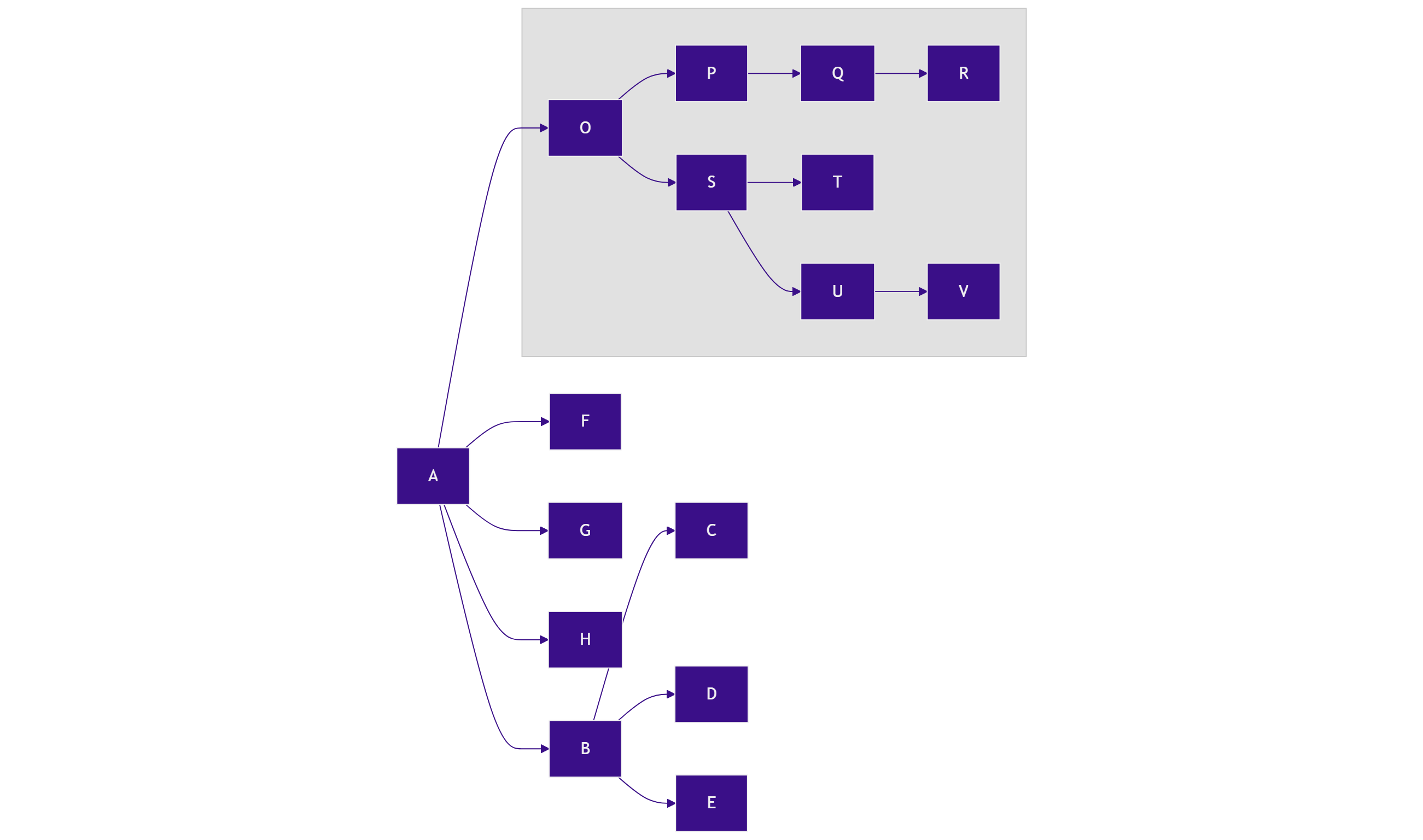
性能提升
通过将包名称和版本转换为唯一整数ID,新算法显著加速了比较操作。最终,它将TeamX的Restore时间从16分钟进一步缩短到仅2分钟!🎉
最终成果与未来展望 🌈
性能与内存对比
以下是新算法相较于优化后的旧算法在不同场景下的表现:
| 场景 | 提升百分比 |
|---|---|
| OrchardCore库 | 提升15%-32% |
| TeamX库 | 提升8倍 |
同时,新算法减少了25%的堆内存分配,为大型项目开发提供了更好的支持。
后续计划
- 增强多框架支持场景下的并行化处理。
- 修复锁定文件相关问题,使新算法适用于更多场景。
- 消除中间文件(如
project.assets.json),简化整个Restore过程。
我们的学习与反思 💡
从优化到重写,这段旅程教会了我们许多关于工程实践和团队协作的重要经验:
- 拥抱挑战:大胆尝试,即使面临未知风险。
- 持续验证:用测试数据驱动决策,快速迭代。
- 团队合作:让新人带来“新眼光”,突破思维惯性。
- 用户至上:始终以用户需求为中心,关注实际效益。
感谢你阅读我们的故事!如果你对NuGet Restore有任何疑问或建议,请通过官方指南与我们联系。希望这些改进能够为你的开发旅程带来更多便利!💻