向量搜索:开启智能信息检索新时代 🌟
在信息爆炸的时代,我们每天都在与各种搜索系统打交道。然而,传统的关键词搜索已经无法满足我们日益复杂的需求。今天,我们带您走进一个全新的搜索领域——向量搜索!✨
向量搜索不仅能找到包含某些关键词的内容,更能基于语义理解挖掘相关信息,让搜索结果更贴合人类思维。比如,当您搜索“快速健康早餐点子”时,它可能推荐“营养丰富的早晨膳食”,即便后者没有出现完全一致的词汇。这背后的秘密就是向量搜索。
什么是向量嵌入?💡
向量搜索的核心是向量嵌入,它将文本、图片或其他数据转换为一组数字(即向量)。这些数字能够捕捉数据的语义关系和复杂含义。过程如下:
- 🧠 将文本或图片输入大型语言模型(LLM)。
- 🔢 LLM将数据转化为向量(数字列表)。
- 🎯 向量表示数据的语义,类似的数据具有相似的数字模式。
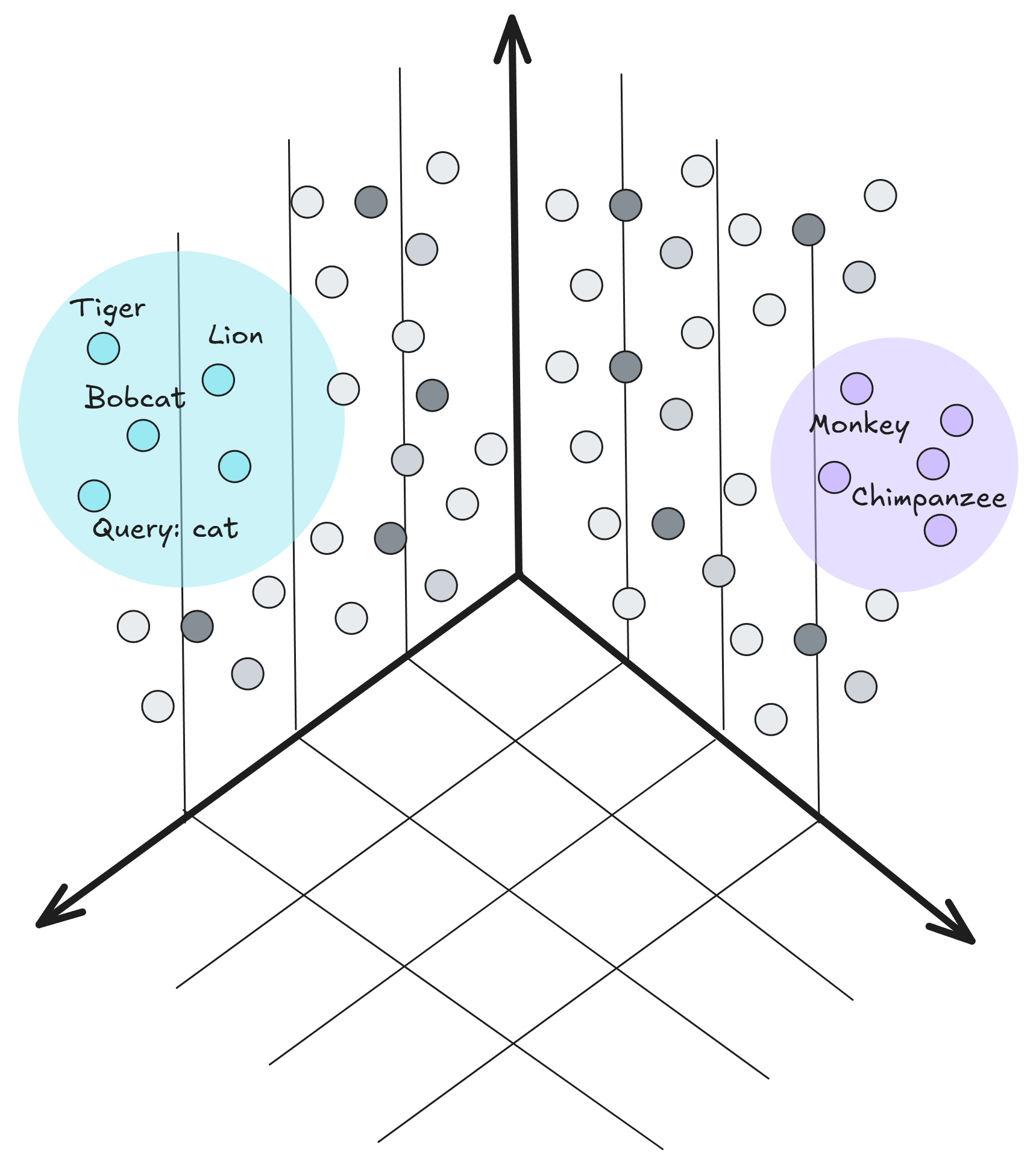
例如,“狮子”和“山猫”的向量会很相似,因为它们都是猫科动物,而“猫”的向量虽然不同,但也有一定相似性。
向量搜索如何工作?🚀
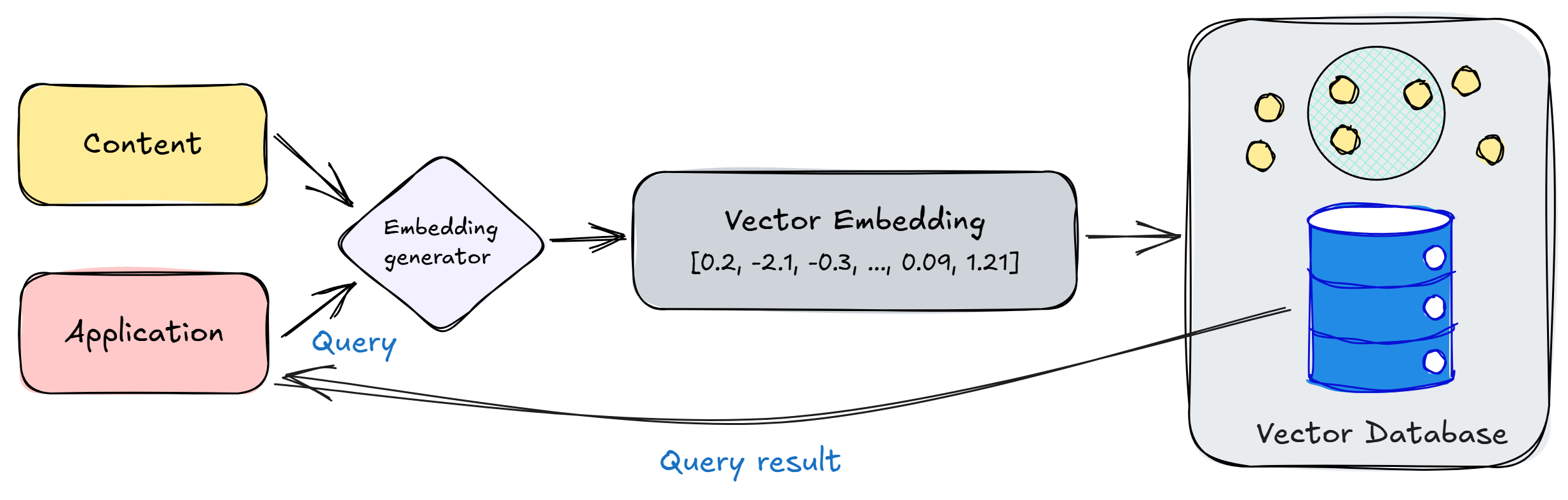
简单来说,向量搜索通过以下步骤实现智能检索:
- 🔍 将您的搜索请求转化为向量。
- 📊 系统将这个向量与数据库中的所有向量进行比较。
- 🌟 找到与搜索向量最相似的数据向量。
- 🖼 返回与相似向量关联的内容,如文章、图片或其他数据。
这种比较依赖于计算向量之间的距离。可以将每个向量看作空间中的一个点,距离越近,语义相似度越高。
向量数据库:高效存储与检索的关键 🗄️
要实现快速、精准的向量搜索,普通数据库显然无法胜任。这时,我们需要专门的向量数据库。它们不仅能存储数百万甚至数十亿个向量,还能通过智能算法实现高效检索。
向量数据库的核心技术是“近似最近邻”(ANN)算法,它能够在不逐一检查所有向量的情况下快速找到最相似的结果。主流向量数据库包括:
- Weaviate
- Pinecone
- Qdrant
此外,您还可以通过扩展PostgreSQL(如pgvector插件)将其变成一个简易的向量数据库。

向量搜索 vs. 传统搜索 🔍
传统关键词搜索通常根据您输入的文字匹配网页内容。例如,输入“红色鞋子”,系统会返回包含“红色”和“鞋子”最多的页面。然而,这种方法有明显局限:
- ❌ 无法识别相关术语(如“猩红鞋履”)。
- ❌ 缺乏上下文理解能力。
- ❌ 不擅长处理复杂问题。
虽然全文搜索比关键词搜索有所改进,但仍然难以捕捉语义关系。而向量搜索弥补了这些不足:
- ✅ 理解上下文与语义关系。
- ✅ 提供相关概念内容。
- ✅ 能够处理复杂问题,如长问题或模糊查询。
因此,向量搜索已经成为现代AI应用的重要基石。例如,它为聊天机器人提供更精准的信息检索,也让推荐系统更加智能化。
总结 📖
向量搜索是信息检索技术的一次飞跃,它通过语义理解为我们打开了一扇通往智能世界的大门。通过将数据转化为代表意义的数字模式,向量搜索能够发现传统关键词方法无法捕捉的潜在关系。
从电商平台到智能助手,向量搜索正在改变我们与数据互动的方式。尽管仍在发展中,它已经让我们的数字工具更加贴心与智能。